
Goodbye Excel sheets, hello Pandas
If you can see how to solve a problem in an Excel spreadsheet, there is a good chance you can do the same in Python using its Pandas library. In today’s article we introduce Pandas and see how similar they are to spreadsheets.
The name “Pandas” comes from “Panel Data” and “Python Data Analysis” and is the standard way to handle data sets in Python.
Pre-requisites
You will Python, which is free to download and its pandas
library. Check your installation works by starting python and running
the following import statement:
$ pip install pandas
:
$ python
Python 3.10.9 (main, Mar 1 2023, 12:33:47) [Clang 14.0.6 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas
>>>
Excel to Pandas
As we have used Excel in our previous articles we are going to continue that theme by doing the same thing in Excel and Pandas. Open Excel and fill some cells as follows. This is going to be our dataset.
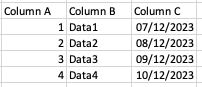
Save this as a CSV (comma separated file). Different versions of Excel
differ but it will be something like Save As on the File menu,
then in the dialog change the file format from .xslx to CSV UTF-8
(Comma-delimited) (.csv). I called my file data.csv. Make sure you
know where that csv file was saved, we are going to load it into
Python next. If you open it in a text editor it should look something
like this:
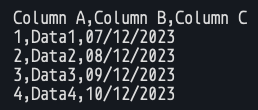
CSV files are very common for report formats and database dumps, so if you intend to process data it is very likely you will come across CSVs. Let’s load it into a Panda. Make sure you are in the same folder as the CSV, then run python:
$ cd example/
$ python
Python 3.10.9 (main, Mar 1 2023, 12:33:47) [Clang 14.0.6 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas
>>>
>>> panda = pandas.read_csv('data.csv')
>>> panda
Column A Column B Column C
0 1 Data1 07/12/2023
1 2 Data2 08/12/2023
2 3 Data3 09/12/2023
3 4 Data4 10/12/2023
>>>
As you can see, the contents of our panda variable is a
spreadsheet-like structure containing the data from the file.
Built-in functions
There is a lot you can do with Pandas, but to start with we are going
to look at their similarity to spreadsheets. In our article on
spreadsheets we started with simple functions such as MAX(). What is
the equivalent in our Panda?
>>> panda['Column A'].max()
4
>>>
If this didn’t work for you, make sure you used the correct type of brackets, [square] then (round), and that your column title is exactly the same as in the file, capitals, spaces and all.
In Excel, we chained together functions by referencing other cells as
the arguments to our functions. For example
IF(J6="MALE",AVERAGE(K6,L6),AVERAGE(M6,N6)) where we change our
calculation based on a what is in cell J6. We can do the same for
one “cell” in our Panda but they are really set-up to handle whole
columns or rows of data. Just as we “copy down” formulae for every row
in a spreadsheet we can apply a function to every row in a
Panda. Let’s double every value in Column A:
>>> panda['Column A'] * 2
0 2
1 4
2 6
3 8
Name: Column A, dtype: int64
That doubled every value but did not do anything with the result, it just gets printed to the terminal. Let’s put the results into a new column:
>>> panda['Twice'] = panda['Column A'] * 2
>>> panda
Column A Column B Column C Twice
0 1 Data1 07/12/2023 2
1 2 Data2 08/12/2023 4
2 3 Data3 09/12/2023 6
3 4 Data4 10/12/2023 8
Writing your own functions
In Excel we wrote our own functions, so let’s do the same in Python,
starting with a function that just prints “Hello, world!”. In Python
the amount of space at the start of a line is important, so ensure the
p of print lines up with the f of def, and don’t forget the
: at the end of the def.
>>> def hello(n):
... print("Hello, world!")
...
>>>
Our function hello takes one argument, which it names n but it
does not use. We now have a hello function. Let’s apply it to our
Panda.
>>> panda['Column A'].apply(hello)
Hello, world!
Hello, world!
Hello, world!
Hello, world!
0 None
1 None
2 None
3 None
Name: Column A, dtype: object
What is going on here is that Hello, world! is being printed to the
terminal each time the function is applied to a row in Column A of
the Panda, and as there are four rows we see it four times. Nothing is
changed by the function so we are just left with Column A which is
also printed to the terminal. We could store the results back into the
Panda instead:
>>> panda['Hello'] = panda['Column A'].apply(hello)
Hello, world!
Hello, world!
Hello, world!
Hello, world!
>>>
Did that work? If we look at the Panda:
>>> panda
Column A Column B Column C Twice Hello
0 1 Data1 07/12/2023 2 None
1 2 Data2 08/12/2023 4 None
2 3 Data3 09/12/2023 6 None
3 4 Data4 10/12/2023 8 None
The Hello column was created but it is empty! Our function prints a
string to the terminal but does not return a value. Let’s fix that.
>>> def hello(n):
... return "Hello, world!"
...
>>> panda['Hello'] = panda['Column A'].apply(hello)
>>> panda
Column A Column B Column C Twice Hello
0 1 Data1 07/12/2023 2 Hello, world!
1 2 Data2 08/12/2023 4 Hello, world!
2 3 Data3 09/12/2023 6 Hello, world!
3 4 Data4 10/12/2023 8 Hello, world!
That’s better. We can now put anything we like into that function (and rename it appropriately of course).
What’s in a name?
Defining a function just so that we can apply it once is a bit
long-winded. For one-off functions we can define the function “on the
fly” in which case we do not have to name it because it is clear to
Python where the function is. We are not referring to a previously
defined function. A nameless function like this is called a “lambda”
which is some obscure jargon from computer science. Let’s do that
again with a lambda function. Python expects the function to take at
least one argument i.e. the value from column A, as it applies it to
each row, but the function does not have to do anything with it. We
can denote unused arguments with an underscore instead of proper name
such as x:
>>> panda['Hello'] = panda['Column A'].apply(lambda _: 'Hello, world!")
>>> panda
Column A Column B Column C Twice Hello
0 1 Data1 07/12/2023 2 Hello, world!
1 2 Data2 08/12/2023 4 Hello, world!
2 3 Data3 09/12/2023 6 Hello, world!
3 4 Data4 10/12/2023 8 Hello, world!
>>>
Save your working
Once we have done some processing the results are sitting in memory and will be lost when we exit our Python session. We usually want to persist them into a file. Just as we can read data into a Panda we can write data out too:
>>> panda.to_csv('results.csv')
>>> [Ctrl-D]
$ cat results.csv
,Column A,Column B,Column C,Twice,Hello
0,1,Data1,07/12/2023,2,"Hello, world!"
1,2,Data2,08/12/2023,4,"Hello, world!"
2,3,Data3,09/12/2023,6,"Hello, world!"
3,4,Data4,10/12/2023,8,"Hello, world!"
That is not quite what we were expecting. Each row has a row number, and there is an empty column title at the start too. We can tell Panda not to do that:
>>> panda.to_csv('results.csv', index=False)
>>> [Ctrl-D]
$ cat results.csv
Column A,Column B,Column C,Twice,Hello
1,Data1,07/12/2023,2,"Hello, world!"
2,Data2,08/12/2023,4,"Hello, world!"
3,Data3,09/12/2023,6,"Hello, world!"
4,Data4,10/12/2023,8,"Hello, world!"
That’s more like it. We are dealing here with CSV files but Pandas can
also read and write Excel files, .xlsx.
2026 Update: ask AI to write your Pandas code
LLMs are particularly good at Pandas. You can describe your data
transformation in English – “Load this CSV, filter rows where age is
over 65, group by department, and show the average wait time” – and
get working Pandas code instantly. This means clinicians can go from a
question about their data to an answer without memorising Pandas
syntax. The concepts in this article (DataFrames, apply, lambda,
read/write CSV) are still worth understanding so you can read and
verify what the AI produces, but you no longer need to remember
whether it is read_csv or load_csv or what index=False
does. Just ask.